

Dog Breed Classification using Deep Learning
Pets occupy a very special place in our households; in most cases they are considered a member of the family. Every time I see a new dog I wonder what breed that dog is. There are more than 300 unique dog breeds in the world, and many dogs are mixed with multiple breeds. As a result, it is often very difficult to know the breed of a dog. But, can we accurately determine a dog's breed using machine learning?
In many cases, this will be a very difficult challenge because even a trained human would have a hard time distinguishing between some breeds of dogs from an image. For example, the Brittany, Irish Red & White Setter, and Welsh Springer Spaniel look very much alike. Another example of breeds that show only slight differences are American Water Spaniel and Curly-Coated Retriever. To add to the potential for confusion, there are many cases of dogs within the same breed that show fairly significant variations (for example, see the American Staffordshire Terrier below).
In this post, I will demonstrate how to use deep learning to try to automatically identify dog breeds from images. This project was inspired by the Udacity Machine Learning Nanodegree program I participated in.








Step 1: Dataset - Break dataset into Training, Testing, and Validation sets
I use the dog dataset from Udacity ,which includes 133 dog breeds with 8,351 total dog images. The data are split into a training set (80%), a validation set (10%), and a test set (10%). The training set is used to determine the best-fit weights for the model, while the validation set allows me to check that the model complexity is appropriate, which means it won't be overfitting or underfitting. Finally, the test set is used only after deciding on the model parameters, to determine the overall accuracy of my model.
The images below are samples of some of the dogs in my dataset. Note that these images are not uniform; many include multiple dogs, people, and other objects. Although it is easy for us as humans to separate the dogs in these images from everything else, it is not super-trivial to train a Neural Network to do the same. However, with a little work, our model could figure out how!

Step 2: Create a Convolutional Neural Network (CNN) to classify Dog Breeds (from Scratch)
With 133 dog breeds in my sample, random chance says that guessing the correct breed has a probability of less than 1%. Thus, as long as the accuracy is higher than 1%, we can say that our model is useful (although maybe not very useful if it is not much higher than 1% :0)
I am going to use Keras , a python library used for deep learning that is particularly popular because it is easy to get up and running.
Step 2-1. Pre-process the Data (Rescale the images)
We will start by pre-processing the data. Keras requires us to input our images as a 4D array (aka a 4D tensor), with the shape
(n_samples, n_rows, n_columns, n_channels)
where `n_samples` corresponds to the total number of images (or samples), and `n_rows`, `n_columns`, correspond to the pixel number of rows and columns for each image, and `n_channels` corresponds to the number of RGB channels for each image, which is 3.
I have a function that takes as input the path to a color image file and converts that image into the proper 4D tensor format to feed into our CNN. It converts the image information (pixel value) into numpy arrays, and resizes each array to make them all uniformly 224 x 224 pixels.

Then, when split into 3 color channels, each image is represented by a 3D array (224, 224, 3).
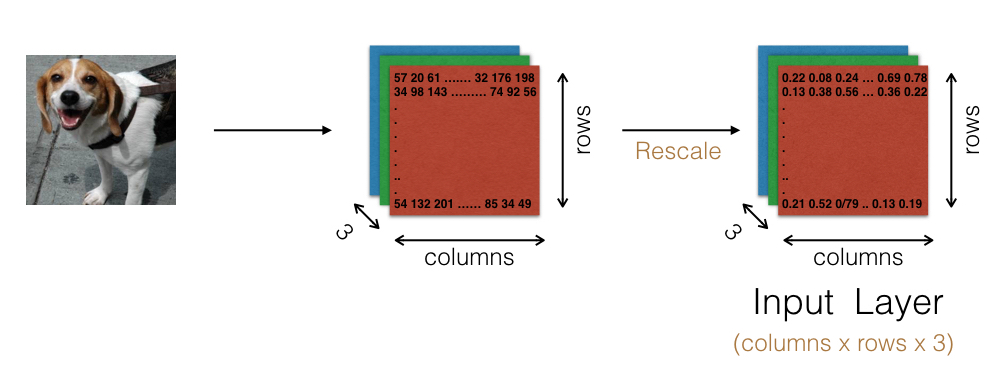
Next, an extra dimension is added to the 3D array to allow for multiple images (samples) to be processed. Thus, the images are handled as 4D tensors. The returned tensor for a single image will always have the shape
(1, 224, 224, 3)
I have another function that takes an array of strings, with each string being the path to an image, as input to convert those images into a 4D tensor with the shape
(n_samples, 224, 224, 3)
Finally, I rescale the images by dividing every pixel in every image by 255, which changes the range of each image from 0-255 into 0-1.
Step 2-2. Define the CNN model architecture
Why CNNs?
Regular Neural Networks use vectors for hidden layers, which don't represent the full images well. In particular, the fully connective layers of a regular neural network are less time efficient and easily lead to overfitting. For example, the scales of the images in our sample are a respectable 224 x 224, which means a hidden layer needs to include 224 x 224 x 3 = 150,528 weights. If we want to use multiple layers (as expected), the number of weights would add up quickly.
On the other hand, CNNs are especially powerful when we must train on multi-dimensional data, such as images. CNNs consist of locally connected layers, which use far fewer weights compared to the densly connected layers of a regular neural network. The locally connected layers efficiently prevent overfitting and allow us to easily understand the image data because they naturally handle two dimensional patterns. You can read more details here.
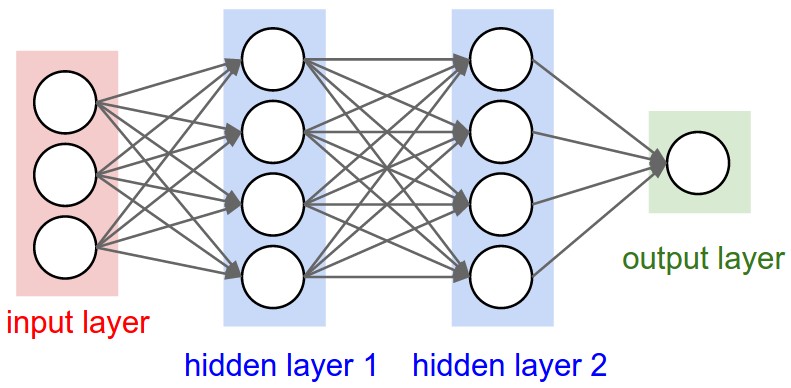
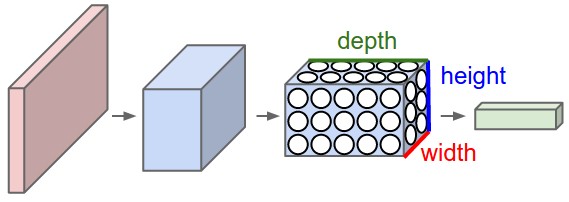
Design of CNN
A CNN consists of multiple layers, which include convolutional, pooling, and some fully connected layers (also used in regular Neural Networks).
(1) Convolutional Layer
A convolutional Layer consists of locally connected nodes, meaning that the nodes are only connected to a small subset of the previous layers' nodes. To build a convolutional layer, we first select a width (column) and height (row) that defines a convolution filter. The filter is a matrix that can have its own characteristic pattern, and each convolutional layer will have the task of searching for its filters pattern in the image. To do this, we simply move the filter horizontally and vertically over the matrix of image pixels, and at each position the convolutional filter returns a numerical result that specifies whether its pattern was seen locally. The image below demonstates how a convolutional layer works. In practice, one will use many convolutional layers, each searching for its own unique pattern in the image, in order to identify complex structures.
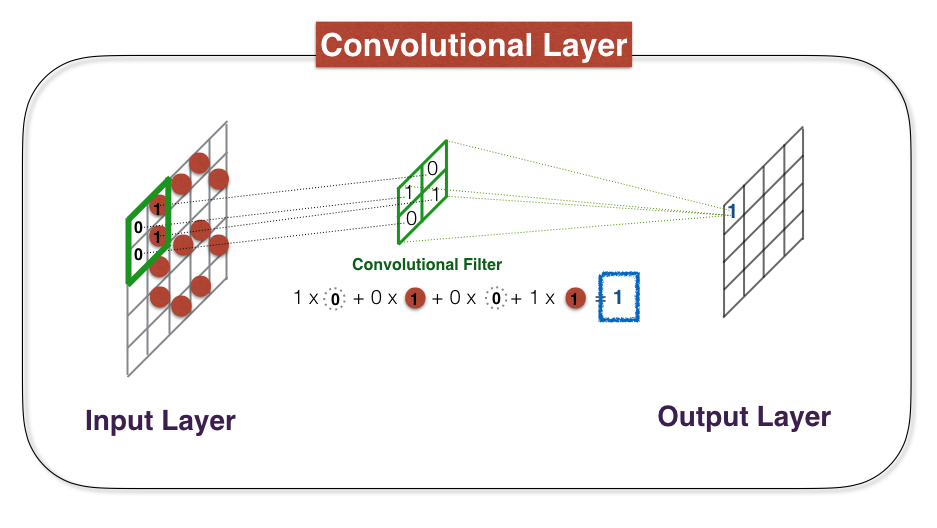
(2) Pooling Layer
Recall that a convolutional layer is a stack of feature maps where we have one feature map for each filter. More filters means a larger stack, which means that the dimensionality of our convolutional layers can get quite large. Higher dimensionality means we will need to use more parameters, which can lead to overfitting. Therefore, we need a method to reduce this dimensionality by using pooling layers within a CNN.
Generally, there are two popular choices for types of pooling layers. The first type is a max pooling layer. Max pooling layers take a stack of feature maps as input, and are constructed by finding the maximum value from a subset of pixels in the input layer. The second type of pooling layer is a global average. As the name implies, this pooling layer simply stores the average of all values in the input layer, rather than considering smaller windows. The global average pooling is a more extreme type of dimensionality reduction.
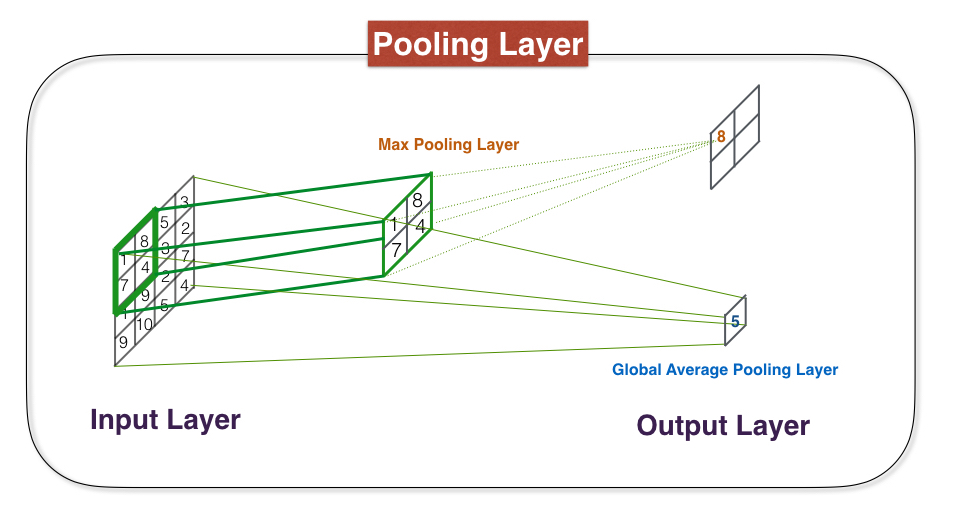
My CNN model architecture
I put three convolutional layers in my CNN, as the figure below shows. The first convolutional layer uses 16 filters, and in general it identifies only very broad patterns. The next convolutional layer has 32 filters, and the third uses 64 filters. These latter layers are used to find more complex shapes and patterns. After each convolutional layer is a max pooling layer used to reduce dimensionality, and after the third max pooling layer is a global average pooling layer. Finally, I use a fully connected layer with a softmax activation function that returns probabilities for each dog breed.
The table below shows the summary of my CNN model.
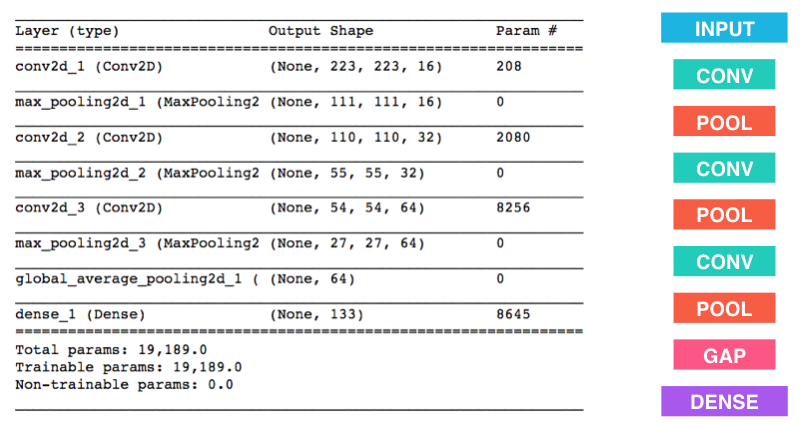
Note that the number of parameters is large, but not prohibitively large (regular neural networks could easily reach millions of parameters).
Step 2-3. Loss function
After designing the CNN model, we need to specify a loss function so that we can quantify the model accuracy. Since we are constructing a multiclass classifier, we will use categorical cross-entropy loss.
This loss function returns a numerical value that is lower if the model predicts the true label (in this case, the correct dog breed). As with other classification tasks in machine learning, we want to minimize the loss function to train our model to give us the highest accuracy possible. The true labels are one-hot encoded, and each label is a vector with 133 entries. The model outputs a vector having 133 entries, where each entry corresponds to the probability of that dog breed.

For example, let's consider the image with a Welsh Springer Spaniel dog. Our model predicts that there is a Brittany in the image with a 90% propability and Welsh Springer Spaniel in the image with a 10% probability. The categorical cross-entropy loss checks the true label vector (with only Welsh Springer Spaniel selected) against the prediction vector (which has 90% chances of Brittany and with only 10% chance of Welsh Springer Spaniel), and returns a high value for the loss. The model then adjusts the weights, and if the prediction changes to favor the true label more, then the loss function decreases. Eventually, if our model is good enough, we would find at the end of our training that it correctly identifies most dog breeds.
Step 2-4. Train the model
In training the model, I modify the weignts to improve the predictions. I chose to train the model for 5 epochs, and I saved the weights that correspond to the highest validation accuracy. This process took around 20 min on my laptop. Expect it to take more time if you want to train your model with a larger number of epochs.
Step 2-5. Load the model and calculate accuracy on test set
Once the training has finished, I load the saved model weights and calculate the classification accuracy on the test set. The accuracy from my CNN model is around 2.4%, which is just a little better than random guessing, and it's not great.
Step 3: Using Transfer Learning
Why Transfer Learning?
As we have seen from the result above, using a CNN model from scratch does not often lead to a satisfying result. The reason our CNN model was not very good at accurately identifying dog breeds is that it lacked sufficient complexity to identify the wide variety of objects in the images. If your model can't tell the difference between a dog, a person, and a tree, then it certainly will not be very good at distinguishing between breeds of dogs. But, what if we could take the foundation of a sufficiently complex neural network that has already been trained to identify objects like dogs and people, and build off of that existing foundation?
This is the basic idea behind transfer learning, which has proven to be a fruitful approach to developing CNNs to perform complex tasks. We can take a CNN model which has already been trained on image data, and use its foundational architecture to apply to a similar problem that we want to solve. If the model has been trained to identify the right kind of object (in this case, dogs), then it can very easily be repurposed for our classification problem. This will save us a great deal of time and effort, because there's no need to reinvent the wheel every time we need to solve a slightly different problem.
There are existing CNN models that have been pre-trained on ImageNet, a database containing nearly 15 million images depicting a vast array of objects and scenes. The models listed below are available in Keras, and they have all been pre-trained on ImageNet. You can click each link to find out more about how you can apply the model you like.
How does it work?
If you take a CNN that has been pre-trained on the ImageNet database, then you can be reasonably confident that your CNN has already learned how to distinguish between the 1,000 different categories of objects that are represented by ImageNet. Most of those categories are animals, fruits, vegetables, and other everyday objects.
You might now be asking yourself: "If I want to use a CNN for a classification task involving something that is not found in the ImageNet database, is it still relevant or beneficial to use that pre-trained CNN knowledge?" The answer is most definitely yes.

The convolutional filters in a trained CNN are arranged in a hierarchy. The filters in the first layer often only detect edges or blobs of color. The second layer might detect circles, stripes, and rectangles. There early features are very generalized, and are typically useful for analyzing any image in any dataset. The filters in the final convolutional layers are much more specific. If there were birds in the training data set, then there are filters that can detect birds. If there were cars or bicycle, there are filters to detect wheels and so on. We will see that it's then useful to remove the final layers of the pre-trained network that are very specific to a particular training data set, while keeping the earlier layers when we do transfer learning. Then, we simply add one or two more layers and train only those final layers on our particular classification task. This is one way to do transfer learning, but your preferred method will depend on both the size of your dataset and the level of similarity it shares with the ImageNet database.
Note that the transfer learning technique will work well if your data set is relatively small and very similar to ImageNet. Our dog data set is appropriately small and it has significant overlap with a subset of the ImageNet categories, which makes it ideal for this application! :-)
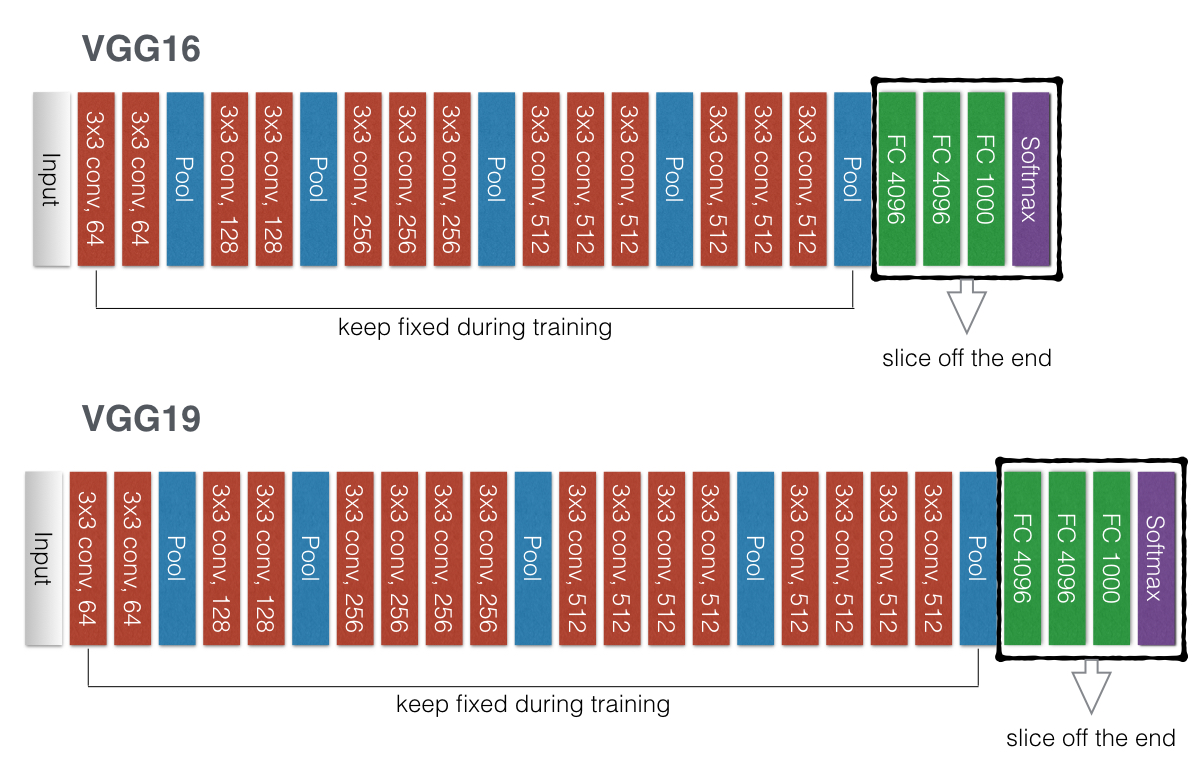
First, we slice off the end of the network (the layers highlighted by black boxes in the figure above) and add a new classification layer with 133 nodes (one for each of our output labels). We then train only the weights in this layer, freezing all the weights in the earlier layers. We can take an image, pass it through the pre-trained model, and stop at the last VGG16/VGG19 max pooling layer. This turns each image into another 3D array, which we can then save as part of a new dataset. Then, when we go to train our network, we will use this new data set as the inputs and our network in Keras will have two layers: an input and an output layer. Thus, our model needs to take as input a 7 x 7 x 512 array for each image. That will result in a lot of parameters, so I also do some dimensionality reduction through a global average pooling layer. The figures below show my CNN architecture when using VGG16 and VGG19 as the pre-trained foundation.
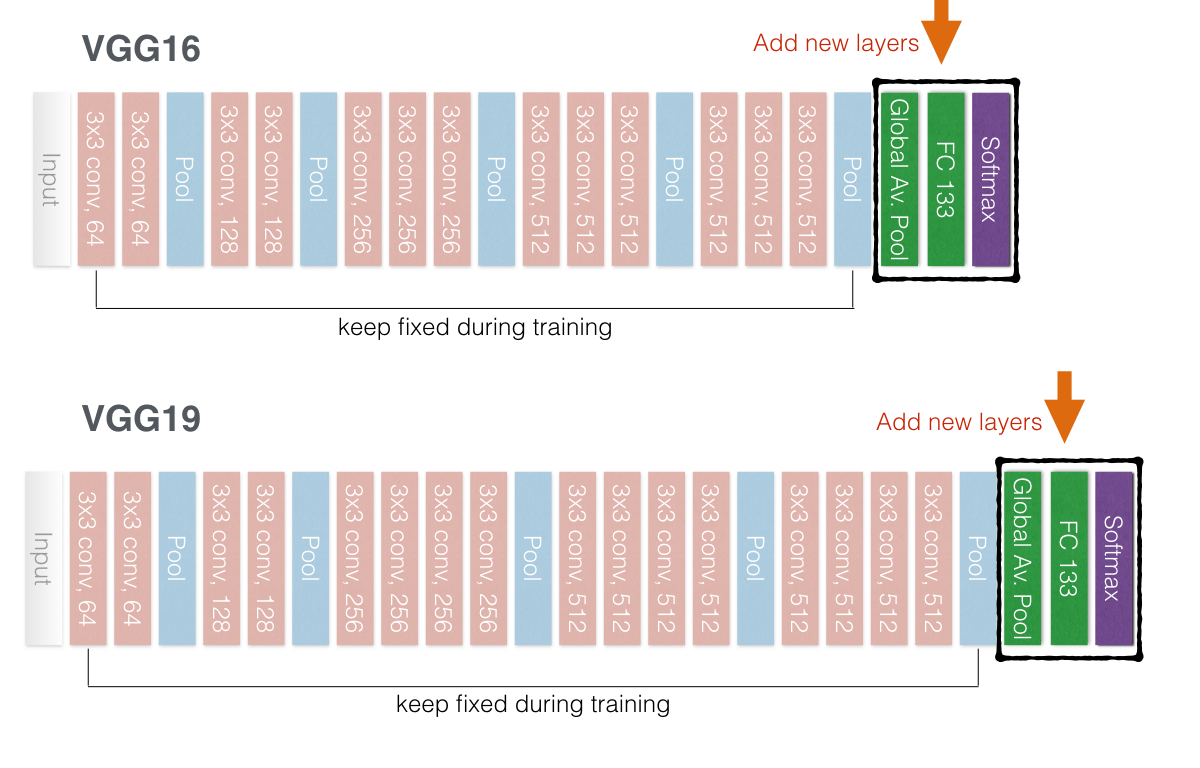
For this project, I used VGG16/19, InceptionV3, and Xception by adding global average pooling layer and fully connected layer with softmax activation functions. Finally, I compiled the models with the same loss function described earlier and I check the accuracies against the test set. Below are the resulting accuracies for each model.
- VGG16 - 45%
- VGG19 - 48%
- InceptionV3 - 80%
- Xception - 84%
Using Xception results in the highest accuracy. Thus, I want to apply the model using Xception to predict dog breed! 84% is not bad, right? :-)
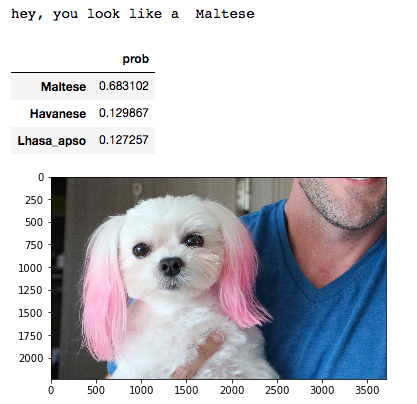
Step 4: Apply the Model to predict dog breed
Mis-predicted dogs
When I apply my model to predict dog breeds, I failed to correctly predict dog breeds for 130 out of 836 test images. The images below show examples of the dogs my model failed to correctly guess. The very left images are the input images, with the correct breed label printed in a white box, while the images to the right show the the dog breeds my model predicted for that dog, sorted by the probabilities assigned by the model. Note that many of the dogs my model fails to accurately predict seem not to be easy to distinguish even with human eyes.
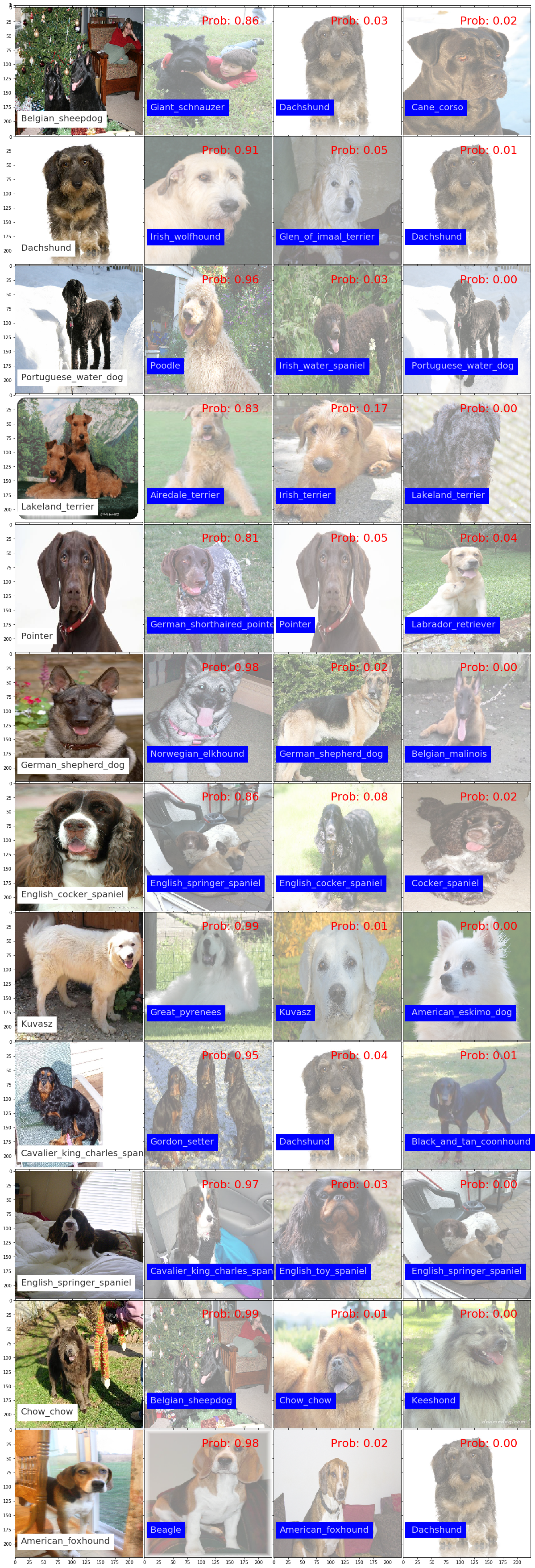
The images show examples of incorrect guesses again, but this time where the prediction probability is less than 0.8. Note that it's even more apparent in these cases that it's really hard for human eyes to find the correct breed.
Based on the fact that my model accuracy is higher than 84%, overall it seems to work pretty well. For example, in the case of the Brittany dogs I mentioned at the very begining, our model predicts the breed correctly for 4 out of 6 test images. This is pretty impressive, considering that their appearance looks very similar to other breeds, such as Welsh Springer Spaniel or Irish Red & White setter. If we have enough GPU memory, I believe I could build an even better model to classify dog breeds after testing with different model architectures. Feel free to train your own model with transfer learning and find an even better model to categorize dog breeds!
How about mixed breeds?
If we test mixed breeds on our model, can it predict at least one of dog breeds for those with mixed breeds? I tested it with several mixed-breed dogs. Out of 7 mixed breeds I used for the testing, only 2 dogs are correctly predicted by the model. The figures below show a subset of the images of mixed breed dogs.
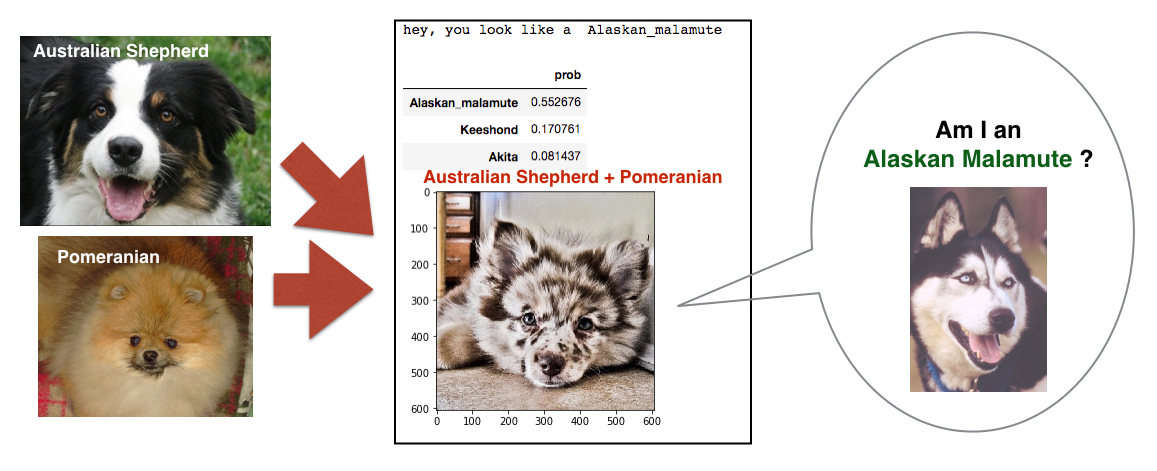
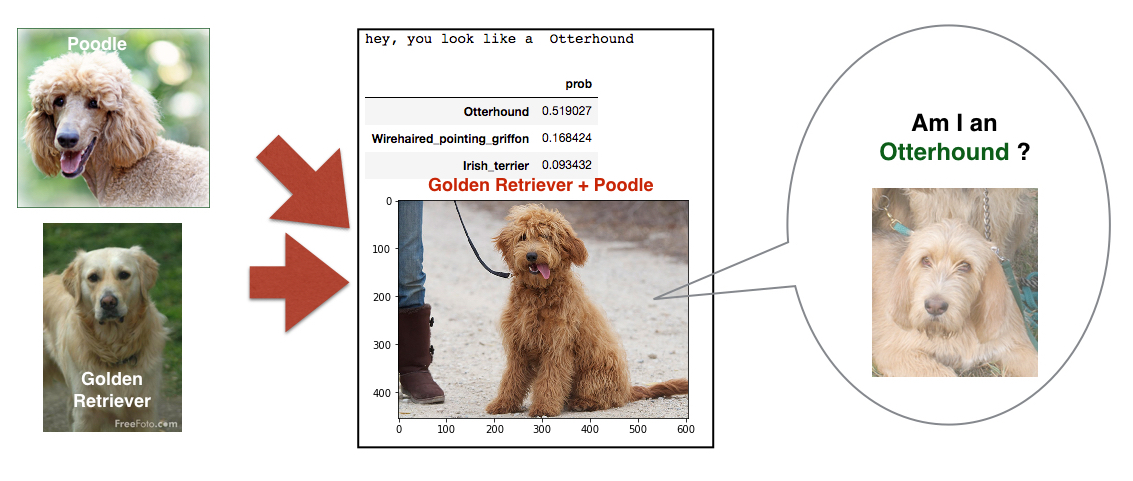
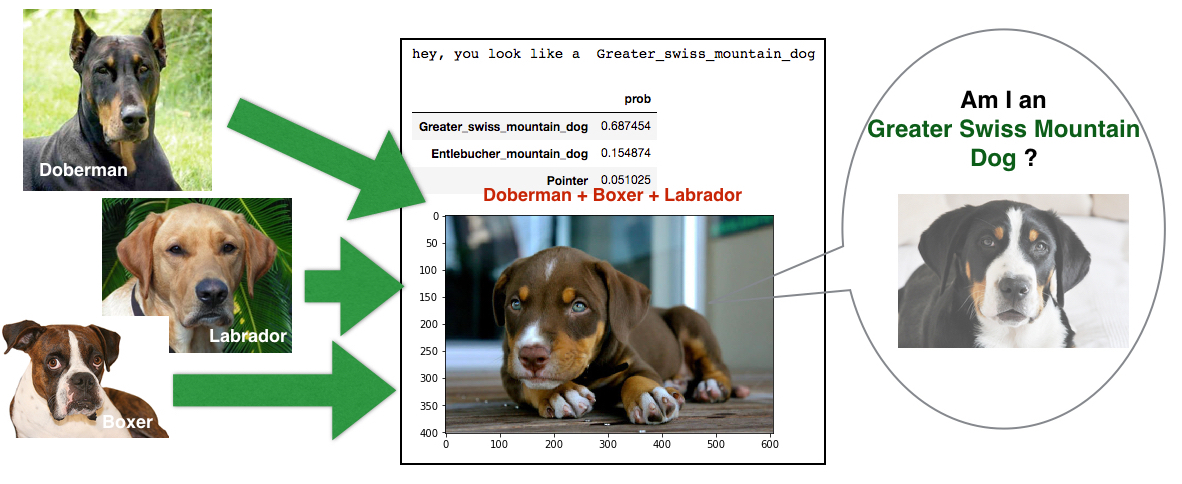
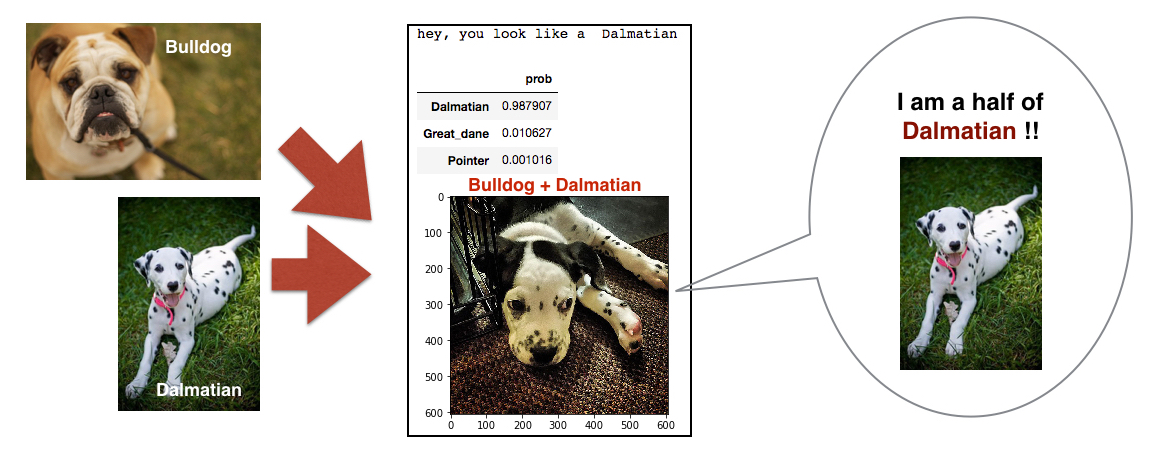
The last figure was correctively predicted. However, the dog (Bulldog + Dalmatian) looks very close to being a pure dalmatian, doesn't it? Thus, I guess it is really hard to predict mixed-breed dogs, although all of the natural breeds for the mixed breeds are trained by my model. In order to categorize mixed-breed dogs, I think we need to put the specific mixed-breed cases as new entries in our training and validation data if we want to do a better job of predicting those mixed-breed cases.
Summary and Future work.
I trained more than 8,000 dog images with 133 different breeds to predict their dog breed automatically
using artificial intelligence.
I designed a CNN model from scratch, and found that the result was not impressive (a little higher than 2%).
Next, I used several different transfer learning models, including VGG, Inception, and Xception,
which finally led to a model with 85% accuracy on the test set with the Xception bottleneck feature.
The result seems to be pretty good, at least similar to (or even better) than human eyes.
There are still problems with categorizing mixed dog breeds, so I believe
we would need to train a model on a wider range of dog breeds, pure and mixed,
in order to build a more generalized neural network to identify the breed(s)
of any dog.

Reference
- Udacity Machine Learning Nanodegree program
- The Lecutre Note of CS231n Convolutional Neural Nerworks for Visual Recognition by Stanford
- Deep Learning: Chap 6. Convolutional Neural Net by Ken'ichi Matsui
- Keras Tutorial in EliteDataScience
- ImageNet: VGGNet, ResNet, Inception, and Xception with Keras by Adrian Rosebrock
- An Intuitive Explanation of Convolutional Neural Networks by ujjwalkarn
- Transfer learning & The art of using Pre-trained Models in Deep Learning by Dishashree Gupta